Оптимизация: Шаг за шагом
Вы администратор Navision. У Вас успешно прошло внедрение системы. Детские болезни успешно преодолены. Можно расслабиться. Проходит некоторое время, и появляются первые сигналы. Сначала не очень тревожные, но с течением времени все более настойчивые и более опасные. Рано или поздно Вы понимаете: надо что-то делать. Пора заняться оптимизацией. Но вопрос: за какую ниточку дергать? Что подправить? Куда вообще смотреть? Открываем просторы интернета и тратим очень много времени на изучение вопросов оптимизации. Даже проводим некоторые опыты, успешные или не очень. Что-то получилось. Проходит еще некоторое время, и опять начинают возникать новые проблемы. И опять нужно изучать вопросы и начинать новый цикл оптимизации. Это, КОГДА-НИБУДЬ закончится? Думаю, нет. Это ветряная мельница оптимизации. Кто-то с ней справляется, а кого-то она перемалывает с косточками.
Почему так сложно? Основная причина в том, что ни одна система не будет похожа на другую. Поэтому большинство советов по оптимизации, которые Вы найдете, являются расплывчатыми и общими. Помогут ли они конкретно в Вашем случае или нет неизвестно, т.к. это напрямую зависит от правильности оценки ситуации Вами или Вашими консультантами.
Оценка ситуации. Начальные условия
В качестве примера взята одна из компаний. ERP NAVISION. В качестве БД используется SQL сервер. Размер БД сотни ГБ. Ведется товарный и финансовый оперативный учет. Ведется учет оптовых и розничных продаж. В месяц добавляется от 1 до 1.8 млн. товарных операций. Количество операций за 4 года 90 млн. Количество записей в справочнике товаров 400 тысяч. В год проводятся операции примерно со 100 тыс. уникальными товарами на 100 складах. Работает большое количество пользователей.
Жалобы. Медленный учет товарных документов. Постоянные блокировки. Медленный ввод строк документов. Долго открываются формы списков документов. Долго просчитываются строки оборотных ведомостей. Долгое выполнение обработок (расчет себестоимости, загрузка продаж магазинов и т.д.). Зависают отчеты или очень долго обрабатываются. Большое количество одновременно запущенных аналитических отчетов вызывают общее замедление работы всей системы.
И вот первый вопрос, который встает перед нами. Что оптимизировать в первую очередь: оперативную работу (ввод документов, учет документов, показ списков и оборотных ведомостей) или аналитическую работу? Сразу замечу, что требование: обеспечить одновременную и эффективную работу в обоих направлениях невозможно реализовать достаточно эффективно. Например: любой отчет, который будет включать в себя анализ неучтённых документов, приведет если не к остановке, то к существенному замедлению работ по вводу новых документов. Создание дополнительных индексов, которые ускоряют работу аналитических отчетов, приводит, в конечном счете, к замедлению ввода данных, причем даже тогда, когда отчеты не запущены. Чем больше индексов — тем хуже обновление и добавление данных. Минусом является рост БД за счет дополнительных индексов. Существенно увеличивается время переиндексации.
Таким образом, появляется первое решение по оптимизации: Необходимо выбрать направление оптимизации: объект или предмет оптимизации. Естественным приоритетом при выборе между аналитической или оперативной работой обладает оперативная работа, т.к. аналитика является следствием качественной и быстрой оперативной работы.
Следствием этого решения является следующее: аналитическая работа должна быть вынесена за пределы оперативной БД.
Конечно, это решение не всегда может быть реализовано на 100% процентов. Всегда будут ситуации, в которых нужно получить самые оперативные аналитические отчеты, даже в ущерб другой работе. Будет еще список VIP пользователей, которым невозможно отказать в возможности запуска аналитических отчетов в оперативной БД. Потому в список ролей добавляется роль «REPORT_RUN», которая разрешает запуск отчетов. Кроме того в список ролей добавляются роли «REPORT XXX» при наличие которых пользователь может запустить аналитический отчет с номером XXX. Все остальные пользователи вынуждены обращаться к аналитической БД для получения отчетов.
Решение о выделении аналитической работы за пределы Navision позволяет Вам подобрать специальную аналитическую систему, которая будет хорошо приспособлена к решению Ваших аналитических задач.
И как следствие: нам необходимо сосредоточится на оптимизации оперативной работы.
Хотя круг вопросов, после выделения аналитической БД, удалось сузить и даже получить временную передышку, нам нужно не терять времени и разбираться с тем, что можно сделать в оперативном учете для ускорения его работы. И тут нужно задуматься: что происходит внутри Navision при выполнении тех или иных задач?
Исследования, поиск причин
В первую очередь необходимо разобраться с теми инструментами, которые у нас есть для получения информации о том, что происходит внутри системы.
Начнем с сервера БД. Первичным инструментом мониторинга является «Системный монитор». Этот инструмент позволяет оценить общее состояние системы в данный момент времени. Я отслеживаю четыре параметра:
- Сведения о процессоре\% загруженности процессора. Если этот показатель достаточно долго близок к 100%, то это значит что, в системе запущен один или несколько сложных аналитических отчетов, расчетных алгоритмов и т.д.
- SQL Server: Buffer Manager\Buffer cache hit ratio – процент попадания запросов в кэш буфера. Чем выше этот процент, тем меньше нужно дополнительных чтений данных с диска. Если этот показатель часто (40% от времени наблюдения) ниже 75% необходимо увеличивать оперативную память.
- SQL Server: Buffer Manager\Page reads/sec – количество операций чтения страниц данных в секунду. Если этот параметр долгое время(больше 20% от времени наблюдения), то какой-то запрос сканирует большой объем данных.
- SQL Server: Buffer Manager\Page writes/sec — количество операций записей страниц данных в секунду. Если вы видите большой пик записи, то это значит, что за последнее время был изменен большой объем данных. Как правило, в этот момент можно наблюдать большое количество блокировок пользователей. Т.о это косвенный показатель блокировок.
Есть несколько моментов, которые нужно учитывать:
— я сторонник чистой системы. Это значит, что один сервер предназначен для решения одной задачи. Очень сложно оценить работоспособность SQL сервера, если на нем параллельно работает почтовый сервер, аналитический сервис и что-то еще. Поэтому предыдущие показатели нужно оценивать только на чистой системе.
— аппаратные средства могут очень сильно отличаться друг от друга. Понаблюдайте за системным монитором в моменты, когда система нагружена слабо и в моменты пиковой загрузки. Тогда Вы начнете понимать, когда в системе идет реальный перегруз и сопоставлять его с теми или иными запросами. Попробуйте запустить запрос расчета остатков на каждом складе для каждого товара и посмотрите на системный монитор. Делайте это в момент покоя после DBCC DROPCLAENBUFFERS. Посмотрите, какой из параметров будет перегружен. Если перегружен процессор, значит нужно увеличивать количество процессоров, система слабая. Если долго читаются данные, значит слабая система I/O. Если при повторении запроса, без DBCC DROPCLAENBUFFERS, падает кэш, значит, не хватает оперативной памяти. Попробуйте так поступить с несколькими сложными, ресурсоемкими запросами. Комбинируйте несколько запросов к разным большим таблицам.
Возможно, Вы примите второе решение по оптимизации: необходим апгрейд аппаратных средств. Однако, всё таки, это еще поспешное решение, т.к. мы еще до конца не разобрались с теми проблемами производительности, которые у нас есть.
Следующий инструмент, который вам понадобиться – это инструмент контроля блокировок. Для этого может вполне подойти Монитор активности в SQL Management Studio. Самое главное при возникновении блокировки разобраться с тем, какой процесс является источником блокировок. Тогда можно обратиться к пользователю и выяснить какую задачу он выполняет, при каких условиях, и заняться оптимизацией этой конкретной задачи. Это сужает поиск причин и позволяет сосредоточить внимание на конкретном процессе.
После того как Вы определили задачу которая является источником проблемы Вам понадобиться следующий инструмент – SQL Server Profiler. Пожалуй, это самый лучший инструмент для понимания процессов, которые происходят в системе. Примерный алгоритм использования:
— Запускаем Navision.
— За один шаг до запуска тестируемого алгоритма (например, перед запуском формы оборотной ведомости по товару) запускаем трассировку профайлером. При этом не забудьте наложить фильтр в свойствах трассировки на поле LoginName. Логин должен быть тем, под которым запущен Ваш Navision.
— Запускаем тестируемый алгоритм в Navision.
— Если в процессе обработки Navision будет показывать «белый экран» ждем до последнего. Дело в том, что профайлер покажет проблемный запрос только после его завершения. Запрос с худшими показателями будет иметь наибольшее значение в поле Duration.
— Обнаружив проблемный запрос, мы можем увидеть, примерно, следующий вид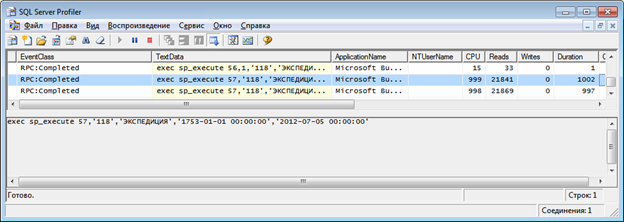
— Сам запрос компилируется один раз, при первой необходимости. Ему присваивается номер, который идет первым параметром в sp_execute (в нашем случае 57). Наша задача найти оригинал запроса. Для этого запускаем поиск и ищем слово «declare» или «sp_prepexec» с первой записи трассировки. Должны найти запрос, во второй строке которого должен быть наш искомый номер.
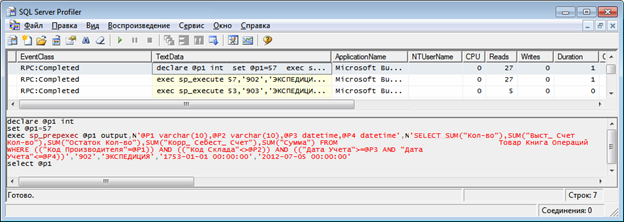
— Запускаем SQL Management Studio и копируем в нее текст запроса, не забывая подставить те параметры, при которых запрос выполнялся долго.
— Строим план выполнения запроса. Начинаем анализ запроса.
Иногда полезно запустить дебагер Navision и пошагово пройтись по какому либо алгоритму просматривая профайлер. Тогда можно наглядно увидеть, как Navision работает с SQL сервером, и разобраться с тем, какой алгоритм лучше использовать в самом Navision.
Анализ и испытания
Итак, у нас есть запрос. Что с ним делать? Необходимо построить план запроса и посмотреть на то, каким образом система будет выполнять этот запрос.
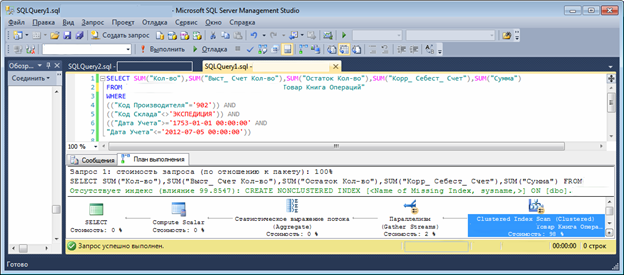
Давайте сначала посмотрим на текст запроса. Это очень характерный для Navision запрос. Цель данного запроса рассчитать shift поля. В списке Select представлены все shift поля, даже если Navision нужно показать значение только одного поля. Такой запрос будет выполняться для каждой строки формы или каждый раз, когда мы будем вызывать функцию calcfields. Сразу замечу, что в новых версиях Navision(2013) способ расчета другой. Там используется индексируемое представление. Способ более грамотный, но все-таки, не самый быстрый.
На что нужно обращать внимание? На то, каким образом система будет производить поиск данных. Есть три варианта:
- Поиск по кластерному ключу/сканирование таблицы
- Фильтрация по индексу с последующим сканированием кластерного ключа
- Поиск в индексе
Первый вариант, как правило, самый медленный, последний самый быстрый. В приведённом рисунке видно, что запрос будет идти по кластерному индексу. Время выполнения запроса 20 секунд. На показ 20 строк понадобиться 6-7минут.
Давайте создадим следующий индекс:
CREATE NONCLUSTERED INDEX [idx_Proizvod]
ON [dbo].[Фирма$Товар Книга Операций]
( [Код Производителя] ASC,
[Дата Учета] ASC
)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE =OFF, SORT_IN_TEMPDB =OFF,
DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON
[Data Filegroup 1]
После создания индекса план запроса измениться: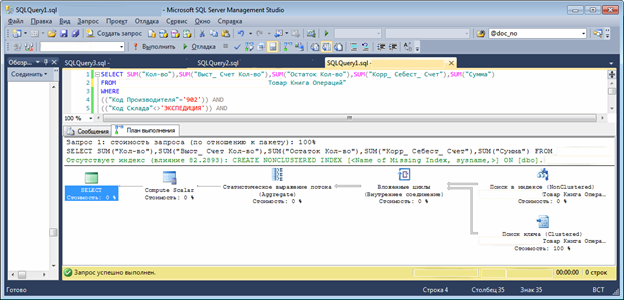
Теперь у нас второй тип поиска — поиск по индексу и фильтрация кластерного ключа. Время выполнения запроса уменьшилось до 3 секунд. Уже хорошо. На показ 20 строк нужна 1 минута.
Давайте поменяем индекс:
CREATE NONCLUSTERED INDEX [idx_Proizvod]
ON [dbo].[Фирма$Товар Книга Операций]
(
[Код Производителя] ASC,
[Дата Учета] ASC,
[Товар Но_] ASC,
[Код Склада] ASC,
[Кол-во] ASC,
[Сумма] ASC,
[Корр_ Себест_ Счет] ASC,
[Выст_ Счет Кол-во] ASC,
[Остаток Кол-во] ASC
)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF,
ONLINE =OFF, ALLOW_ROW_LOCKS =ON, ALLOW_PAGE_LOCKS=ON) ON
[Data Filegroup 1]
После создания индекса план запроса будет такой: 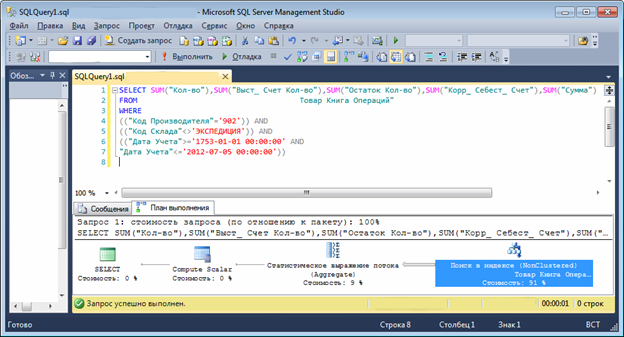
Теперь у нас третий тип поиск – поиск по индексу. Время выполнения запроса около 1 секунды. На показ 20 строк нужно <20 секунд.
Таким образом, мы существенно улучшили быстродействие данного конкретного запроса. Так можно исследовать большинство алгоритмов Navision и найти оптимальные ключи для решения конкретной задачи. Любой вариант этого индекса можно создать непосредственно в Navision.
Принимаем четвертое решение оптимизации: необходимо улучшить работу всех долго работающих алгоритмов за счет построения ключей покрывающих длительные запросы.
Это благодарная работа, ведь с каждым новым индексом мы наблюдаем ускорение работы конкретного пользователя, который даже говорит иногда спасибо. Проходит еще некоторое время, каждый раз, когда нам нужно улучшить конкретный алгоритм мы добавляем новый индекс и в конечном итоге видим следующую картину в списке индексов:
- Код Склада, Дата учета, Источник Но, …… — это индекс Navision
- Код Товара, Код Склада, Закзаз Но, ….. – это индекс Navision
- Источник Но, Код Товара, Дата Учета, …. – это для алгоритма 1
- Дата учета, Код Отдела, Код проекта, …. – это для отчета XXX
- Код Товара, Код Склада, Код Проекта, …. – это для расчета себестоимости
- И т.д.
Индексов стало слишком много. Объем базы существенно вырос, ведь индексы нужны именно в самых больших таблицах. Это уже начинает сказываться на учете и увеличивается время и количество блокировок. Кроме того сам Navision использует большое количество индексов, которые используются в большом количестве форм и отчетов. Как улучшить ситуацию не перерывая весь код Navision?
Пришло время принять пятое решение оптимизации: необходимо создать оптимальную индексную модель, исключив ненужные и дублирующие индексы.
Продолжение следует.
Автор: Владимир Викол
Количество статей, опубликованных автором: 5. Дополнительная информация об авторе появится вскоре.
—Цель данного запроса рассчитать shift поля.—
не shift, а sift (Summary Index Fields Technology)